Adaptive categorization of visual scenes is essential for AI agents to handle changing tasks.
Unlike fixed common categories for plants or animals, ad-hoc categories, such as things to sell at a garage sale, are created dynamically to achieve specific tasks.
We study open ad-hoc categorization, where the goal is to infer novel concepts and categorize images based on a given context, a small set of labeled exemplars, and some unlabeled data.
We have two key insights:
1) recognizing ad-hoc categories relies on the same perceptual processes as common categories;
2) novel concepts can be discovered semantically by expanding contextual cues or visually by clustering similar patterns.
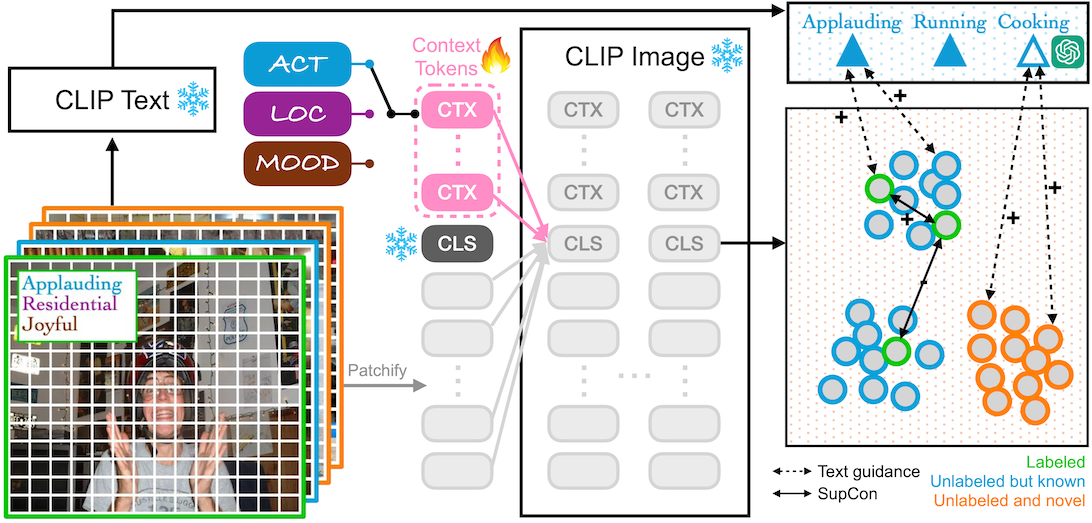
We propose OAK, a simple model that introduces a single learnable context token into CLIP, trained with CLIP's objective of aligning visual and textual features and GCD's objective of clustering similar images.
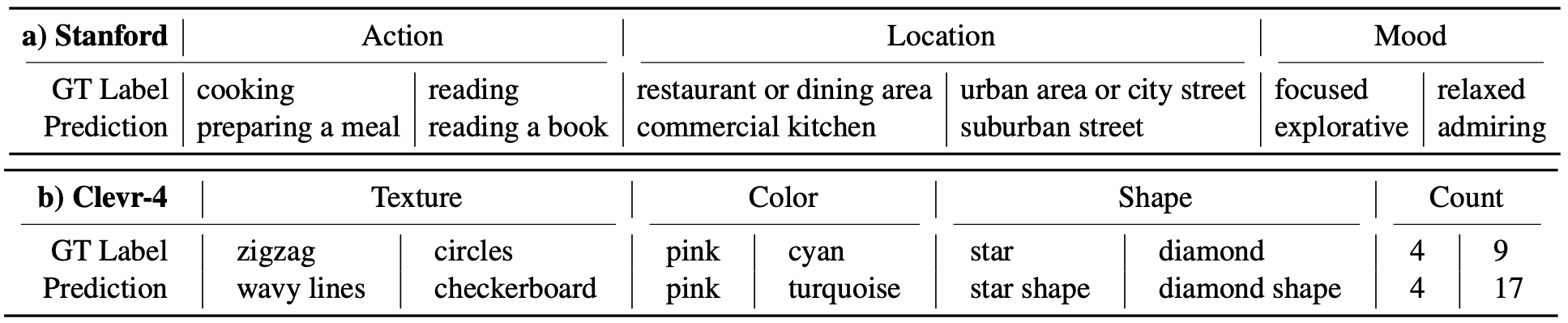
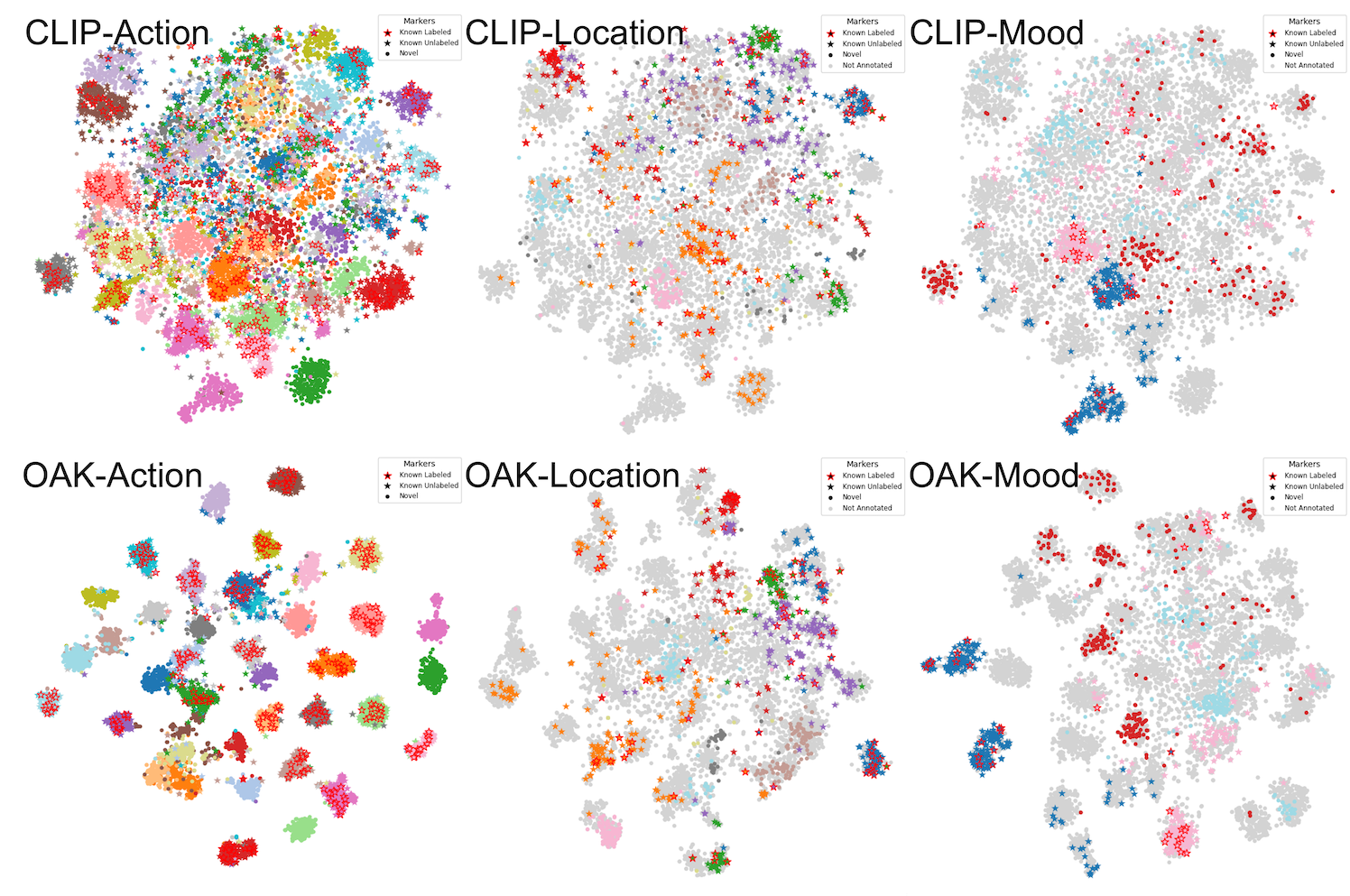
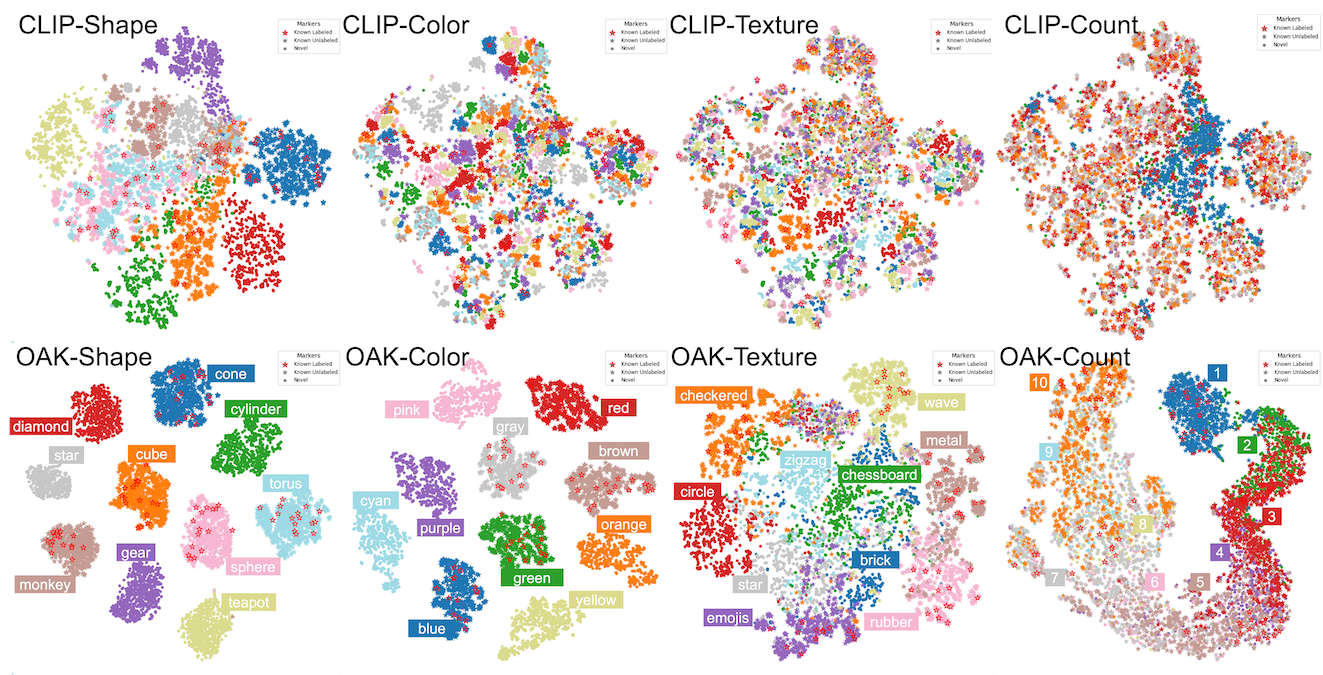
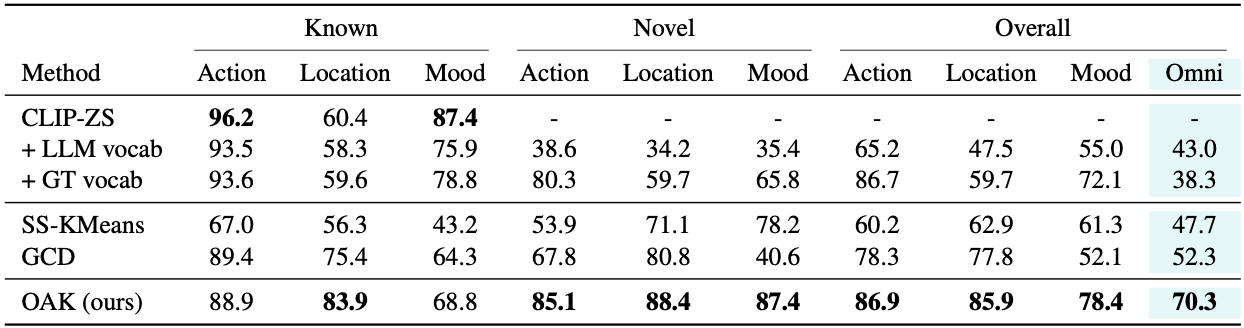
On Stanford and Clevr-4 datasets, OAK consistently achieves the state-of-art in accuracy and concept discovery across multiple categorizations, including 87.4% novel accuracy on Stanford Mood, surpassing CLIP and GCD by over 50%.
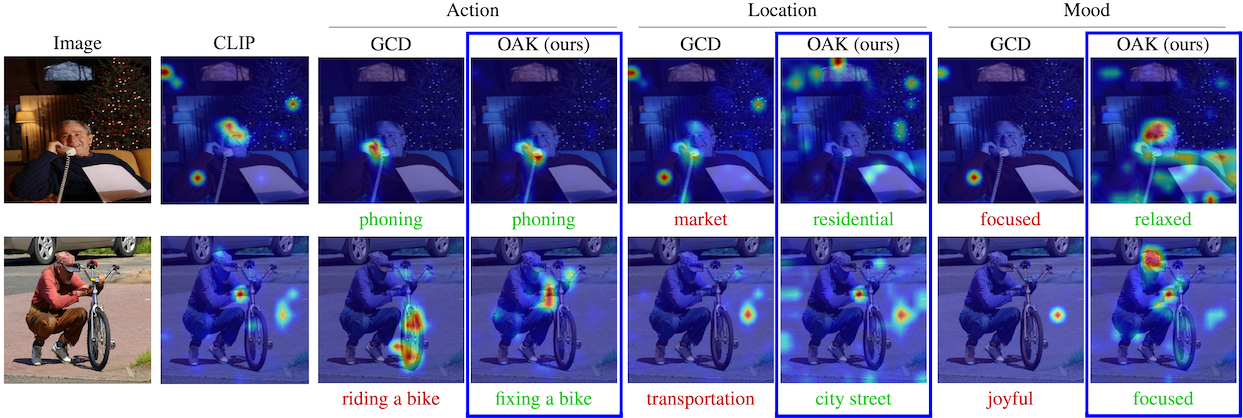
Moreover, OAK generates interpretable saliency maps, focusing on hands for Action, faces for Mood, and backgrounds for Location, promoting transparency and trust while enabling accurate and flexible categorization.
 OAK: Open Ad-hoc Categorization with Contextualized Feature Learning
OAK: Open Ad-hoc Categorization with Contextualized Feature Learning